
From Abracadabra to Zombies
Book Review
 The
Conscious Universe: The Scientific Truth of Psychic Phenomena
The
Conscious Universe: The Scientific Truth of Psychic Phenomena
by Dean Radin
(HarperOne 1997)
part five
In chapter 4, Radin explains how he understands and uses meta-analysis. To him, meta-analysis is the goose that eats garbage and lays golden eggs. Contrary to R. Barker Bausell, Radin does not see meta-analysis as a form of publication bias. Rather, Radin takes it to be a way of measuring how much replication has taken place. I am unaware of anyone else who sees meta-analysis as a form of replication of scientific studies. Most think of it as a way of measuring whether there is likely to be something significant going on in a causal relationship, even if the effect is very small. He calls meta-analysis “the analysis of analyses,” but I don’t think it involves the analysis of any analysis; it is a way of using statistical formulae to try to squeeze statistical significance out of a sample of studies.
Radin makes several questionable analogies in this chapter. One we’ve already mentioned: he compares batting averages of players, teams, and leagues with psi performances of individuals, groups, and groups of groups. The analogy fails because, while there is little disagreement about the reliability and meaning of the data in baseball, the reliability and meaning of the data of psi experiments is almost always highly questionable. We’re never really sure what the data of a psi experiment represent. We know what it means for a player to hit .357, but we don’t know what it means for a subject, a group, or group of groups to get 34% correct at card guessing when 25% is predicted by chance. I’ll get to the other questionable analogies shortly. First, however, we’ll look at how he sees scientific research.
Radin discusses four different ways of reviewing research but does not make it clear what his distinctions mean, nor does he make it clear why we need to know about these distinctions. The only one that matters is meta-analysis. He tells us that it “is a structured technique for exhaustively analyzing a complete body of experiments” (my emphasis). This is misleading because no meta-analysis can know it is either exhaustive or complete. Most, in fact, involve a process of eliminating some studies from consideration, as well as acknowledging that it can’t be complete because it is likely that most negative outcome studies have not been published (the file-drawer effect). (He dismisses the file-drawer effect as not important because he has a statistical formula that shows the number of studies that would have to be unpublished to mitigate the results of the meta-analyses he considers would have to be staggeringly high.) His claim is also misleading because, as Radin himself notes, the reviewer must evaluate various studies in terms of such things as the experimenters, the controls, the number of subjects in the study, where it was published (if it was published), and the overall similarity and quality of the studies.
Radin dismisses in a single sentence the concern over bias and oversimplification in reviewing studies by complaining that “critics are everywhere” (p. 54), as if that were a bad thing! As Ray Hyman notes in his review of the ganzfeld studies (Hyman 1989): he (Hyman) and Charles Honorton disagreed in their evaluation of the quality of many of the studies Honorton included in his meta-analysis. Many of these disagreements were based on what Hyman saw as inadequate randomization techniques. He also criticized Honorton for not including a number of studies and for not noting that there is a tendency to publish the results of studies with small samples only if the results are positive. In short, Hyman found a number of flaws in studies that Honorton didn’t see as flaws (see Hyman 1989 pp. 42-44).
Radin describes meta-studies as comparing apples and oranges to learn something about fruit. This is another bad analogy. The studies brought together for analysis should not be like apples and oranges. If they are, then one batch must be discarded. You want all the studies to be about one type of thing, not about two types of things from which you plan to generalize to some more general thing! You don’t look at 25 studies on aspirin and 25 on statins to generalize to something about pills!
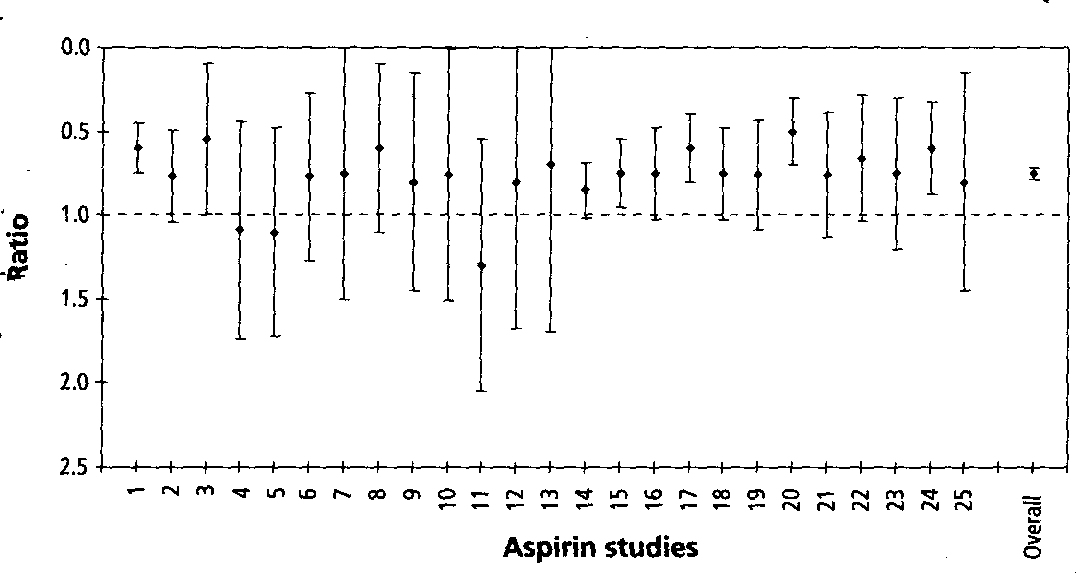
His only example of a meta-study in this chapter is one done on aspirin where the confidence interval of .99 was used (there is one in one hundred chance that the results are a fluke). No psi experiment has used such a high standard. If he used the usual .95 confidence interval (a one in twenty chance the results are a fluke), most of these aspirin studies would have been statistically significant. The aspirin studies do provide us with a good example of how a meta-analysis can provide strong evidence for the significance of data, even if there are several cases of studies with negative results. Radin uses a number of graphs to try to demonstrate his points about meta-analysis. His use of visual data is misleading, in my opinion, and deserves extensive commentary, which I’ll provide below.
I think he makes a false analogy by comparing the aspirin studies with psi studies. First, the aspirin studies use a higher standard (99% confidence interval) than any psi study (95%). Second, the meaning of the data is much less unambiguous in the aspirin studies.
Radin finishes the chapter with a comparison of the hard sciences and the social sciences regarding accuracy of measurements. Again, this is a bad analogy because the hard sciences use higher standards than the social sciences; the tools of measurement are usually more precise in the hard sciences, but the items being measured (like properties of subatomic particles) are difficult to measure. The hard sciences may have much more precise criteria for determining what measurements to throw out. But, in any case, this is all irrelevant to evaluating meta-analyses. This point is relevant to the larger issue of the accuracy of measurement, but the comparison to psi research is a major stretch, since it is never clear exactly what is being measured in psi experiments.
Radin’s Visual Misrepresentation and Distortion of Data
Radin’s visual presentation of data as point estimates within a confidence interval is at best confusing, and at worst misleading and disinformative. His first graphic is on page 34 and purports to depict Mickey Mantle’s “true skill level” as a batter. Anyone familiar with baseball batting averages will find nothing of interest in this graphic. Visually, it does not convey any information or facts as well as a line graphic of Mantle’s batting average each year compared to some baseline stat, such as the average batting average of all American League centerfielders. The concept of “true skill level” is meaningless in this context.
Furthermore, no statistician would apply confidence intervals to one ballplayer’s batting average. What does it mean to say that when Mantle hit .257, his true skill level was between .235 and .310 at the 95% confidence interval? It’s gibberish.
When Radin depicts his first meta-analysis (on page 55) it is not of any psi study but of a meta-analysis of twenty-five aspirin studies. [Click here to view his graph.] Here, his data point estimates within a confidence interval is not irrelevant and silly as it is with the Mickey Mantle example. Rather, his approach is now completely misleading because it hides the significance and information conveyed by the data of those 25 studies. His visual does not show that there were 22,071 physician-subjects in those studies and that there were 104 heart attacks among the 11,037 subjects in the aspirin group and 189 heart attacks among the 11,034 subjects in the placebo group. His visual does not depict that the odds of this difference being due to chance are on the order of 100,000 to 1. His visual doesn’t convey that there were 44% fewer heart attacks in the aspirin group or even that there were 85 fewer heart attacks in the aspirin group. Sure, only 0.94% of the aspirin group had heart attacks, while 1.71% of the placebo group had heart attacks. This may not seem like much of a difference, but since in the U.S. more than half a million people die each year of heart disease and 80% of heart disease deaths in people under 65 are due to first heart attacks, this means that an aspirin a day could save tens of thousands of lives each year. (Of course, they're not saved for eternity. Those who don't die this year will eventually die, probably of heart disease. How much actual benefit will result from taking a daily aspirin is difficult to calculate. That it is likely to produce a benefit in those who have heart disease is a good bet. How much benefit is impossible to tell.)
The way Radin depicts the data, only five of the twenty-five studies showed positive results (i.e., at the 99% confidence interval had both their extremes on the positive side of the graph). One wonders why he portrays this data at the 99% confidence interval, instead of at the usual 95%. Perhaps it had something to do with the fact that most of these studies would then have their extremes on the positive side of the graph, thereby nullifying his point that a bunch of studies that are unimpressive can be impressive when lumped together. While his point that “the aspirin effect was declared to be ‘real’ based on the combined results of all studies” is true, he is wrong to imply that in the case of the aspirin studies most of the individual studies were unimpressive or didn’t show a positive effect. Thus, his conclusion that “this is exactly what meta-analysis has done for psi experiments” is a gross exaggeration.
So, not only is the visual display of this data misleading, it is disinformative. It does not reveal the dramatic effect of aspirin on preventing first heart attacks. Furthermore, Radin doesn’t even mention that the aspirin studies were stopped in midstream because the data was so convincing that it would have been unethical to have continued the study and not offered the benefit of aspirin to those in the placebo group, as well as to make known the findings to the general public. Thus, had the studies been carried out to completion, it is likely that at the 95% confidence interval, the vast majority of the studies would have supported the positive effect of aspirin.
Radin has tried to depict the aspirin study as similar to the psi studies: take a bunch of losers, lump them together, and declare them a winner. It’s as if you could take 20 years of batting averages below .250, lump them together, and somehow magically produce a lifetime average of .357.
By the way, there have been more aspirin studies published since Radin’s book came out in 1997 and the replication is impressive. I’ll mention just one. In 2003 a study found that aspirin reduces the risk of a first heart attack by 32 percent. The research was done at Mount Sinai Medical Center & Miami Heart Institute (MSMC-MHI) and was published in the Archives of Internal Medicine. The study was a meta-analysis of five major randomized clinical trials involving 55,580 participants, including 11,466 women. The researchers also found that aspirin reduces the combined risk of heart attack, stroke, and vascular death by 15 percent.
Nothing similar has come out in psi research, though Radin has continued to abuse the concept of meta-analysis. In his latest book (Entangled Minds: p. 276), he did a mega-meta-analysis of over 1,000 studies on dream psi, ganzfeld psi, staring, distant intention, dice PK, and RNG PK. He concluded that the odds against chance of getting his results are 10104 [that's 10 with 104 zeroes after it] against 1. Radin seems to think he can build the Taj Mahal out of scraps from the junk yard. He's actually built a hologram out of swamp gas in a moonbeam.
end of part five
more book reviews by R. T. Carroll
* AmeriCares *


{kind=link}